Strategies for Deploying Veneur
At Stripe I lead the Observability team and one of our responsibilities is the care and feeding of what we call the observability pipeline. This “pipeline” is a work in progress, but lynchpin of our effort is an OSS project called Veneur.
What Is Veneur?
Veneur is a global aggregator for push-based metrics. It receives “pushed” metrics via UDP — although TCP and TLS are supported! — and aggregates them before sending them to a sink such as Datadog or InfluxDB. Veneur aims for a few goals that make it unique:
- Compatible with StatsD or DogStatsD clients
- Efficient by using fixed memory, reasonable approximations using t-digest and HyperLogLog
- Allows global percentiles and sets by merging from multiple machines
- Scales horizontally through host-local presence and metric hashing
Global Aggregation
There are two types of veneur instance: local and global. Locals receive metrics from clients and only send them to a sink. Globals receive metrics from other Veneurs and send them to a sink.
How do globals do this? Let’s talk about counters first. They are easy because addition is commutative. We can just allow all our machines to write those values to the sink and add them up there. Gauges are “last write wins” within a flush period so locals can do that too. Both of these metrics are submitted directly to the sink from the local instances.
Here’s where globals come in: Histograms and timers — which are the same thing under the hood — are represented using a t-digest data structure which allows us to represent a histogram in a fixed amount of memory by making some tradeoffs on accuracy. Another powerful feature of the t-digest is that it is mergeable so we can collect histograms from multiple sources and create a global instance.
Lastly for sets we use a HyperLogLog to count up uniqueness. It’s also mergeable and works in fixed memory!
The Catch(es)
The first catch is that any metrics you merge have an additional delay that is equal to your flush period. By default this is 10 seconds. This happens because Veneur treats the forwarded metrics like normal metrics and, after merging them, flushes them at the end of the current flush period.
The second catch is that deployment is more involved than Datadog’s host-local agents or StatsD’s single global instance. This post is all about how to handle deploymet.
How Do You Deploy It?
I’m glad you asked! There are 3 major ways you can run Veneur. It was designed to scale up with an organization. As such, I’ll present them in the order you might deploy them.
Single, Central Veneur
You can treat Veneur like a StatsD or Brubeck instance and run it on a single box that all your clients report to. This will work just fine for a small number of hosts or metrics. Veneur is written with this sort of performance in mind and was built to process packets quickly. We no longer test or benchmark this configuration however, so there are no long term guarantees. Luckily the packet read loop is important for all cases so we’ll keep it fast.

This is a novel deployment because it means you have global metrics just like StatsD. You can try this with a Datadog agent’s DogStatsD but in our experience the python-based agent is not performant or efficient enough for more than a few machines’ metrics. Even Veneur will eventually start dropping pacets because there are only so many UDP packets a single machine can handle. This works better if you control your hardware and can configure NICs and such!
Simple Per-Host
Run Veneur on all your hosts and point your service’s *StatsD clients at localhost. Each Veneur will dutifully flush it’s metrics to a remote place, such as Datadog.
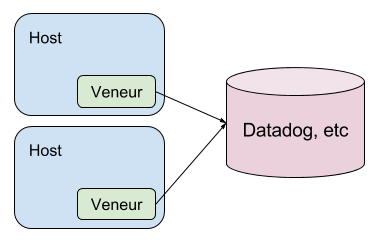
This is a very simple model to deploy, assuming deploying to every machine is easy! It scales well, since there’s no central aggregation. You can also point the flush to a set of load-balanced proxies to control egress.
The downside is that all of your aggregations will be per host. If you wanted to, say, time an API endpoint across all machines in your service you’d have to aggregate percentiles which is mathematically suspect at best.
Central Aggregator
If you want central aggregation, you can deploy a special Veneur instance that acts as an aggregator for forwarding.
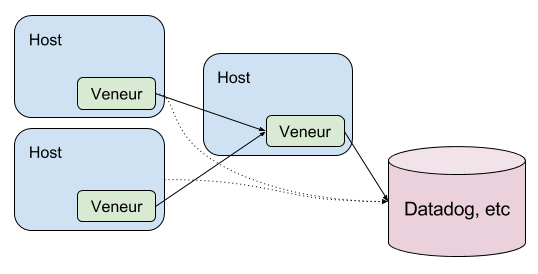
In this arrangement you have a single central instance of Veneur that acts as an aggregator for all “global” metrics: histograms, sets and other things you might designate as global. This has the delightful side effect of globally computed aggregations, but the consequence of being a single point of failure. Fortunately you can plan for this. If you run some additional veneur instances as warm standbys and place them behind a load balancer — careful to only allow one to be active at a time — you can route clients to a healthy instance in the event of failure. This is reasonable because of the flush interval: Veneur only aggregates for the default 10s. Afterward, you can use a different instance!
To accomplish this:
- Set up a global instance
- Configure your local veneur instances’
forward_addressto that of the global.
How Does Merging Work?
When a local instance flushes it gathers up any “global” metrics it has — the aforementioned histograms and sets, but also some other metrics that are opted in using magic tags. Those global metrics are then forwarded to the global instance over HTTP. The global instance receives these metrics at a /import endpoint and merges them into it’s local metrics. It then flushes these merged metrics when the interval expires just like any others.
Proxy and Hashing
Lastly, you can run veneur-proxy in conjunction with Consul.
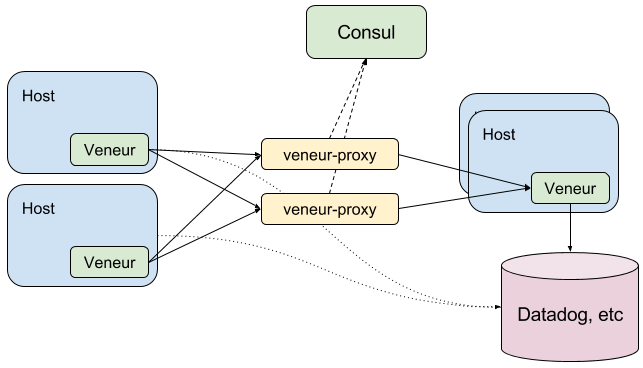
In this arrangement your clients use simple DNS load balancing to statelessly forward metrics to whichever proxy their silicon heart’s desire. The proxy pulls part the metrics, hashes each one and consistently chooses the same global aggregator using consistent hashing.
The ring is populated by discovering up nodes via Consul service discovery. This is more work to set up, especially if you don’t already have consul, but has some nice consequences:
- Your clients remain simple and do not need to know anything about metric sharding/hashing
- You can add and remove global instances and everything keeps working
- You can add and remove proxy instances and everything keeps working
This removes all single points of failure from the deployment, but you have some some weird results for one or two aggregation periods as metrics move inside the ring.
To accomplish this:
- Spin up some global instances, register them with Consul
- Spin up some veneur proxy instances, configure their
consul_forward_service_nameto the service above. Optionally register them with Consul too. - Set your local veneur’s
forward_addressto a Consul DNS, normal DNS or a load balancer that round-robins the veneur proxies.
Other Novel Methods
Because Veneur is built on mergeable structures, you can sort of compose it in other interesting ways. Here are two we’ve thought of:
Global tree
We’ve not tested this, but in theory you could chain together multiple global instances by having you clients report to one, then configure that global to have a forward_address to another global. You can do this as deeply as you want, but each addtional global adds a 10 second delay.
Running Proxy On Each Box
You could run veneur-proxy locally on each of your boxes in a sort of metrics-like-Envoy situation. This allows you to avoid running separate proxy instances but means that you’ll have a lot of machines hitting your Consul API to find health global instances. Beware of that!
Summary
Thanks for taking the time to read this!
Veneur was built to grow with an organization from one central aggregator up to a network of highly scalable, efficient aggregators for tens of thousands of machines. It’s unique combination of performance and flexibility make it great choice if your observability stack is — or if you want it to be — push-based, write-time aggregated.
If you have questions, comments or suggestions I encourage you to create an issue in Veneur and let us give you a hand. We’re also happy to take feature requests and pull requests if you’re using Veneur.
Cheers!
Subscribe via RSS!